Vertrauen zu Large‑Language‑Model‑Klassifikatoren hinzufügen
Large Language Models sind erstaunlich gut bei Zero‑Shot‑ und Few‑Shot‑Klassifikation, aber wie sicher ist das Modell? Lernen Sie, wie Sie versteckte Signale in gut kalibrierte Vertrauenswerte umwandeln, denen Ihr Unternehmen vertrauen kann.
Vertrauen zu Large‑Language‑Model‑Klassifikatoren hinzufügen
Large Language Models (LLMs) sind erstaunlich gut bei Zero‑Shot‑ und Few‑Shot‑Klassifikation: von der Kennzeichnung toxischer Kommentare bis zum Routing von Support‑Tickets. Doch die erste Frage unserer Kunden nach der Demo ist: „Wie sicher ist das Modell?"
In regulierten, kundenorientierten oder risikoreichen Bereichen reicht ein reines Label nicht aus-Sie benötigen eine Wahrscheinlichkeit, die Sie in eine Risikomatrix, einen QA‑Workflow oder ein Dashboard einfügen können. Nachfolgend zeigen wir, wie Sie die in jedem LLM versteckten Signale in gut kalibrierte Vertrauenswerte umwandeln, denen Ihr Unternehmen vertrauen kann.
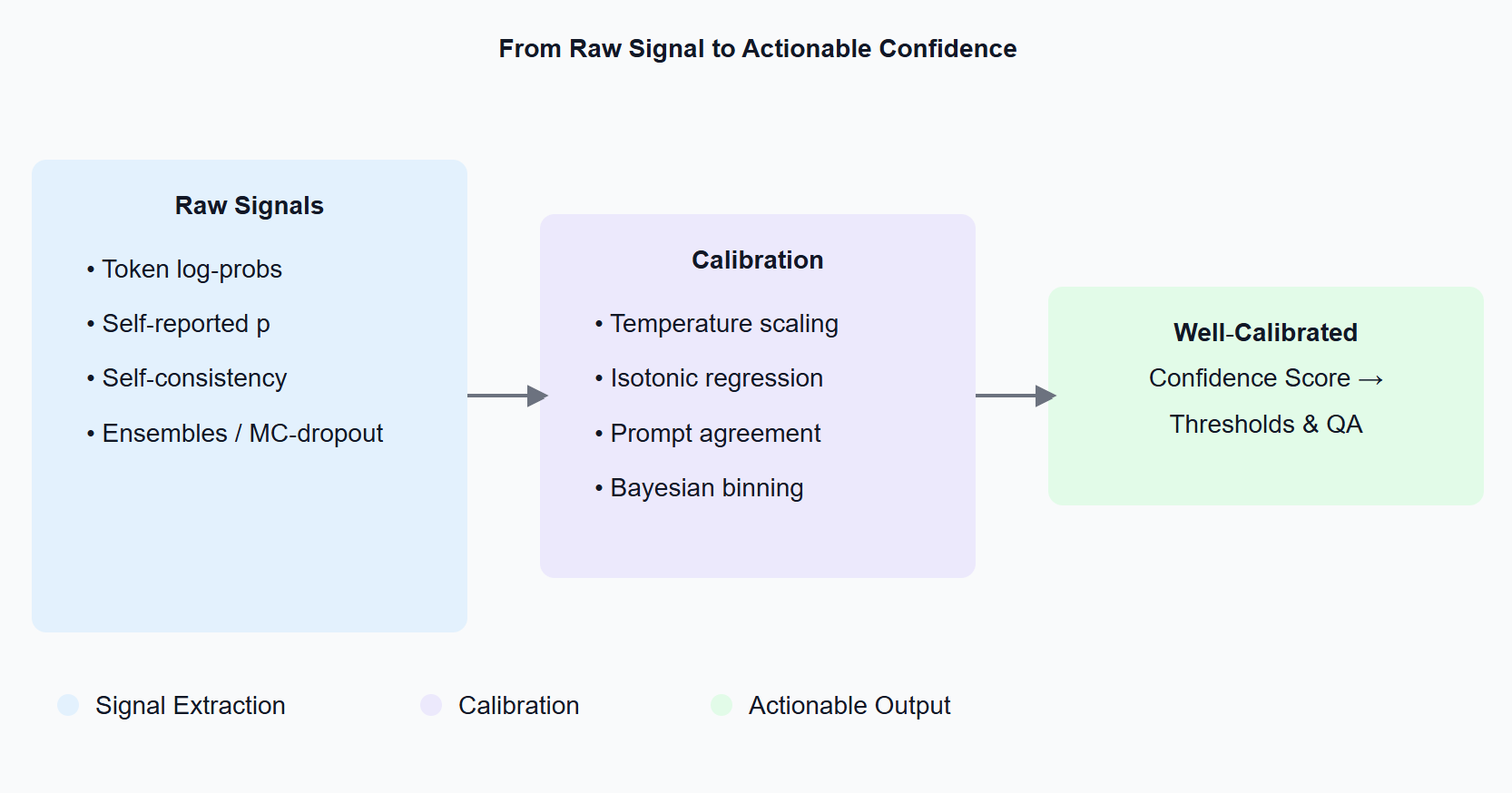
Confidence Measures Diagram
1 Der Einsatz: Warum Vertrauen wichtig ist
Stellen Sie sich einen Zollabfertigungs‑Workflow vor, der Warenbeschreibungen automatisch klassifiziert. Eine 90%‑sichere Fehlklassifikation löst eine manuelle Überprüfung aus; eine 99%‑sichere geht glatt durch. Ohne kalibrierte Wahrscheinlichkeiten überfluten Sie entweder Menschen mit Fehlalarmen oder, noch schlimmer, lassen kostspielige Fehler durchrutschen. Vertrauenswerte verwandeln „Black‑Box‑Magie" in eine auditierbare Komponente Ihrer Entscheidungspipeline.
2 Woher kommen Vertrauenssignale?
Token‑Log‑Wahrscheinlichkeiten. Die meisten Modell‑APIs (OpenAI, Anthropic, Mistral, llama‑cpp, ...) geben Logprobs zurück, wenn Sie das Flag setzen. Aggregieren Sie die Wahrscheinlichkeitsmasse, die jedem Klassen‑Token zugewiesen wird-das ist Ihr Rohwert.
Selbst berichtete Wahrscheinlichkeiten. Sie können einfach fragen: „Geben Sie das Label und eine Wahrscheinlichkeit zwischen 0 und 1 an." Das Modell wird gehorchen-überraschend gut, aber meist übermäßig selbstbewusst.
Self‑Consistency‑Sampling. Prompt das Modell mehrmals erneut oder nehmen Sie mehrere Stichproben. Wenn die Antworten nicht übereinstimmen, behandeln Sie dies als Unsicherheit (siehe SelfCheckGPT).
Ensembles & MC‑Dropout. Klassische Modell‑Unsicherheitstricks funktionieren noch: Führen Sie mehrere Checkpoints aus oder aktivieren Sie Dropout bei der Inferenz, um eine Verteilung von Logits zu erhalten.
3 Von Rohwerten zu zuverlässigen Zahlen: Kalibrierung 101
LLMs neigen dazu, von Haus aus falsch kalibriert zu sein (der 80%‑Vertrauensbereich könnte nur zu 60% der Zeit richtig sein). Post‑hoc‑Kalibrierung behebt das:
- Temperatur/Platt‑Skalierung – lernen Sie einen Skalar T auf einem Validierungsset; teilen Sie Logits durch T.
- Isotonische Regression – eine nicht‑parametrische monotone Abbildung für Multi‑Klassen‑Aufgaben.
- Prompt‑Agreement‑Kalibrierung – mitteln Sie Log‑Probs über verschiedene Templates.
- Bayesianisches Binning oder Ensemble‑Temperatur‑Skalierung – am besten für sicherheitskritische Bereiche.
Bewerten Sie mit Expected Calibration Error (ECE) oder Brier Score; streben Sie ECE < 2% bei gehaltenen Daten an.
4 Praktisch: Kalibrierung eines Zero‑Shot‑Spam‑Klassifikators
Das folgende Snippet zeigt das Wesentliche:
import openai, numpy as np, json, math
LABELS = { "A": "spam", "B": "not spam" }
def classify(text, T=1.0):
prompt = f"Klassifizieren Sie den folgenden Text als A) Spam oder B) kein Spam.\nTEXT: {text}\nAntworten Sie mit einem einzigen Buchstaben."
resp = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=[{ "role": "user", "content": prompt }],
logprobs=True,
top_logprobs=5,
temperature=0
)
# erfassen Sie die Logprob für das erste Token (A oder B)
first_tok = resp.choices[0].logprobs.content[0]
logps = resp.choices[0].logprobs.token_logprobs[0]
# in dict {token: p} umwandeln
probs = {tok: math.exp(lp / T) for tok, lp in zip(first_tok, logps) if tok in LABELS}
Z = sum(probs.values())
probs = {LABELS[tok]: p/Z for tok, p in probs.items()}
return max(probs, key=probs.get), probs
Was passiert:
- Wir fordern Logprobs von der API an.
- Wandeln sie in linearen Raum um und temperatur‑skalieren.
- Normalisieren und geben ein ordentliches {Label: Wahrscheinlichkeit}‑Wörterbuch zurück.
Sammeln Sie ~200 gelabelte Beispiele, passen Sie T auf einem gehaltenen Split an (minimieren Sie negative Log‑Likelihood), und Sie haben kalibrierte Spam‑Wahrscheinlichkeiten, die Sie in der Produktion schwellenwerten können.
5 Häufige Fallstricke
Kleine Kalibrierungssets. Unter ~100 Beispielen dominiert die Varianz; bootstrap‑mitteln Sie ECE, um sie zu verfolgen.
Verteilungsverschiebung. Überprüfen Sie die Kalibrierung erneut, wenn sich Datenquellen oder Prompt‑Templates ändern.
Übermäßiges Selbstvertrauen durch Few‑Shot‑Priming. Zusätzliche Beispiele steigern die Genauigkeit, machen aber oft die Kalibrierung schlechter-passen Sie T erneut an, wann immer Sie den Prompt anpassen.
6 Wenn Log‑Probs nicht verfügbar sind
Wenn Ihr Anbieter Token‑Wahrscheinlichkeiten verbirgt, greifen Sie auf selbst berichtetes Vertrauen oder Self‑Consistency‑Sampling zurück. Beide korrelieren mit Genauigkeit; beide profitieren von den gleichen Kalibrierungstricks.
7 Wichtige Erkenntnisse
- Vertrauenswerte verstecken sich bereits in Ihrem LLM-extrahieren und kalibrieren Sie sie.
- Temperatur‑Skalierung ist eine 10‑Zeilen‑, hohe‑ROI‑Lösung.
- Verfolgen Sie immer ECE/Brier bei frischen Daten.
- Texterous kann kalibriertes LLM‑Vertrauen in Ihre bestehenden Pipelines integrieren-kontaktieren Sie uns, um Ihren Anwendungsfall zu besprechen.
Weiterführende Literatur
- Desai & Durrett (2020) Calibration of Pre‑trained Transformers
- Jiang et al. (2023) Self‑Check: Detecting LLM Hallucination via Argument Consistency
- Minderer et al. (2023) Improved Techniques for Training Calibrated Language Models