Renforcer la confiance des classifieurs à grands modèles de langage
Les LLM excellent en classification, mais à quel point le modèle est-il sûr ? Voici comment obtenir des scores de confiance calibrés pour la matrice des risques, le QA ou le pilotage.
Renforcer la confiance des classifieurs à grands modèles de langage
Les grands modèles de langage (LLM) excellent en classification zero-shot ou few-shot : modération de contenu, routage de tickets, etc. Pourtant, après une démo, notre première question des clients est : « À quel point le modèle est-il sûr ? »
Dans les domaines réglementés, orientés client ou à haut risque, un simple label ne suffit pas — il faut une probabilité exploitable dans une matrice des risques, un workflow QA ou un tableau de bord. Voici comment transformer les signaux déjà présents dans le LLM en scores de confiance bien calibrés, dignes de confiance pour votre organisation.
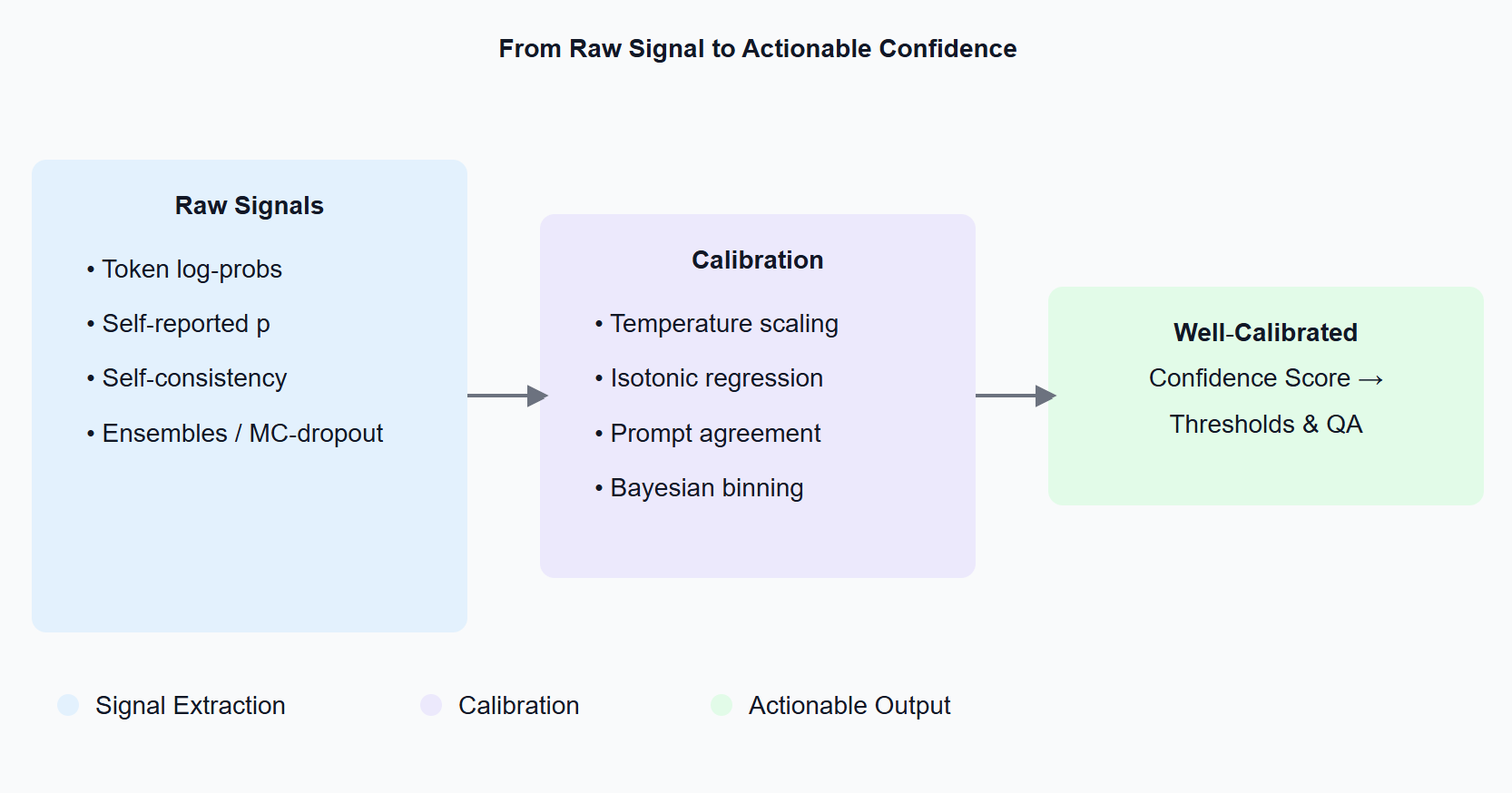
Confidence Measures Diagram
1 Les enjeux : pourquoi la confiance compte
Imaginez un workflow douanier qui classe automatiquement des descriptions de marchandises. Une erreur « sûre à 90 % » déclenche une revue manuelle ; une erreur « sûre à 99 % » passe sans contrôle. Sans probabilités calibrées, vous submergez les équipes de faux positifs ou, pire, laissez passer des erreurs coûteuses. Les scores de confiance transforment la « magie boîte noire » en brique auditable de votre chaîne de décision.
2 D’où viennent les signaux de confiance ?
Log-probabilités des tokens. La plupart des API (OpenAI, Anthropic, Mistral, llama‑cpp, …) exposent les logprobs si vous activez l’option. Agrégez la masse de probabilité sur les tokens de classe — c’est votre score brut.
Probabilités auto-déclarées. Demandez simplement : « Donnez l’étiquette et une probabilité entre 0 et 1. » Le modèle obtient tempérairement de bons résultats, mais est souvent trop confiant.
Échantillonnage et cohérence. Relancez ou échantillonnez plusieurs fois : si les réponses divergent, traitez cela comme de l’incertitude (voir SelfCheckGPT).
Ensembles & MC‑dropout. Les techniques classiques d’incertitude restent valables : plusieurs checkpoints ou dropout à l’inférence pour obtenir une distribution sur les logits.
3 Des scores bruts à des nombres fiables : calibration 101
Les LLM sont souvent mal calibrés d’office (le bucket « 80 % de confiance » n’a peut‑être raison que 60 % du temps). La calibration a posteriori corrige cela :
- Scaling de température / Platt — apprendre un scalaire T sur un jeu de validation ; diviser les logits par T.
- Régression isotonique — mapping monotone non paramétrique pour le multi-classe.
- Calibration par accord de prompts — moyenne des log‑probs sur plusieurs modèles de prompt.
- Binning bayésien ou température d’ensemble — adapté aux domaines safety‑critical.
Évaluez avec l’Expected Calibration Error (ECE) ou le score de Brier ; visez ECE < 2 % sur des données tenues à l’écart.
4 En pratique : calibrer un classifieur spam zero-shot
Le fragment ci-dessous illustre l’idée :
```python import openai, numpy as np, json, math
LABELS = { "A": "spam", "B": "not spam" }
def classify(text, T=1.0): prompt = f"Classez le texte suivant comme A) spam ou B) non spam.\nTEXTE: {text}\nRépondez par une seule lettre." resp = openai.ChatCompletion.create( model="gpt-4o-mini", messages=[{ "role": "user", "content": prompt }], logprobs=True, top_logprobs=5, temperature=0 ) first_tok = resp.choices[0].logprobs.content[0] logps = resp.choices[0].logprobs.token_logprobs[0] probs = {tok: math.exp(lp / T) for tok, lp in zip(first_tok, logps) if tok in LABELS} Z = sum(probs.values()) probs = {LABELS[tok]: p/Z for tok, p in probs.items()} return max(probs, key=probs.get), probs ```
En pratique :
- On demande les logprobs à l’API.
- On passe en espace linéaire et on applique la température.
- On normalise et renvoie un dictionnaire {label: probabilité} propre.
Collectez ~200 exemples étiquetés, ajustez T sur une partition tenue à l’écart (maximiser la log‑vraisemblance), et vous obtenez des probabilités spam calibrées, prêtes pour des seuils en production.
5 Pièges fréquents
Jeux de calibration trop petits. En dessous de ~100 exemples, la variance domine ; moyennez l’ECE par bootstrap pour suivre l’évolution.
Dérive de distribution. Recalibrez quand les sources de données ou les prompts changent.
Surconfiance due au few-shot. Plus d’exemples améliorent parfois la justesse mais dégradent la calibration — réajustez T à chaque modification de prompt.
6 Quand les log‑probs ne sont pas disponibles
Si votre fournisseur masque les probabilités de tokens, revenez aux probabilités auto‑déclarées ou à l’échantillonnage de cohérence. Les deux corrèlent avec la justesse et bénéficient des mêmes techniques de calibration.
7 Points clés
- Les scores de confiance sont déjà dans votre LLM : extrayez-les et calibrez-les.
- Le scaling de température tient en quelques lignes — ROI élevé.
- Surveillez toujours ECE/Brier sur des données récentes.
- Texterous peut intégrer une confiance LLM calibrée dans vos pipelines existants : contactez-nous pour votre cas d’usage.
Pour aller plus loin
- Desai & Durrett (2020) Calibration of Pre‑trained Transformers
- Jiang et al. (2023) Self‑Check: Detecting LLM Hallucination via Argument Consistency
- Minderer et al. (2023) Improved Techniques for Training Calibrated Language Models