Vertrouwen Toevoegen aan Large‑Language‑Model Classificeerders
Large Language Models zijn verbazingwekkend goed in zero‑shot en few‑shot classificatie, maar hoe zeker is het model? Leer hoe u verborgen signalen omzet in goed gekalibreerde vertrouwensscores die uw bedrijf kan vertrouwen.
Vertrouwen Toevoegen aan Large‑Language‑Model Classificeerders
Large Language Models (LLMs) zijn verbazingwekkend goed in zero‑shot en few‑shot classificatie: van het markeren van toxische opmerkingen tot het routeren van support‑tickets. Toch is de eerste vraag die onze klanten stellen na de demo: "Hoe zeker is het model?"
In gereguleerde, klantgerichte of hoog‑risico domeinen is een ruw label niet genoeg-u heeft een waarschijnlijkheid nodig die u in een risicomatrix, een QA‑workflow of een dashboard kunt plaatsen. Hieronder laten we zien hoe u de signalen die in elke LLM verborgen zitten kunt omzetten in goed gekalibreerde vertrouwensscores waar uw bedrijf op kan vertrouwen.
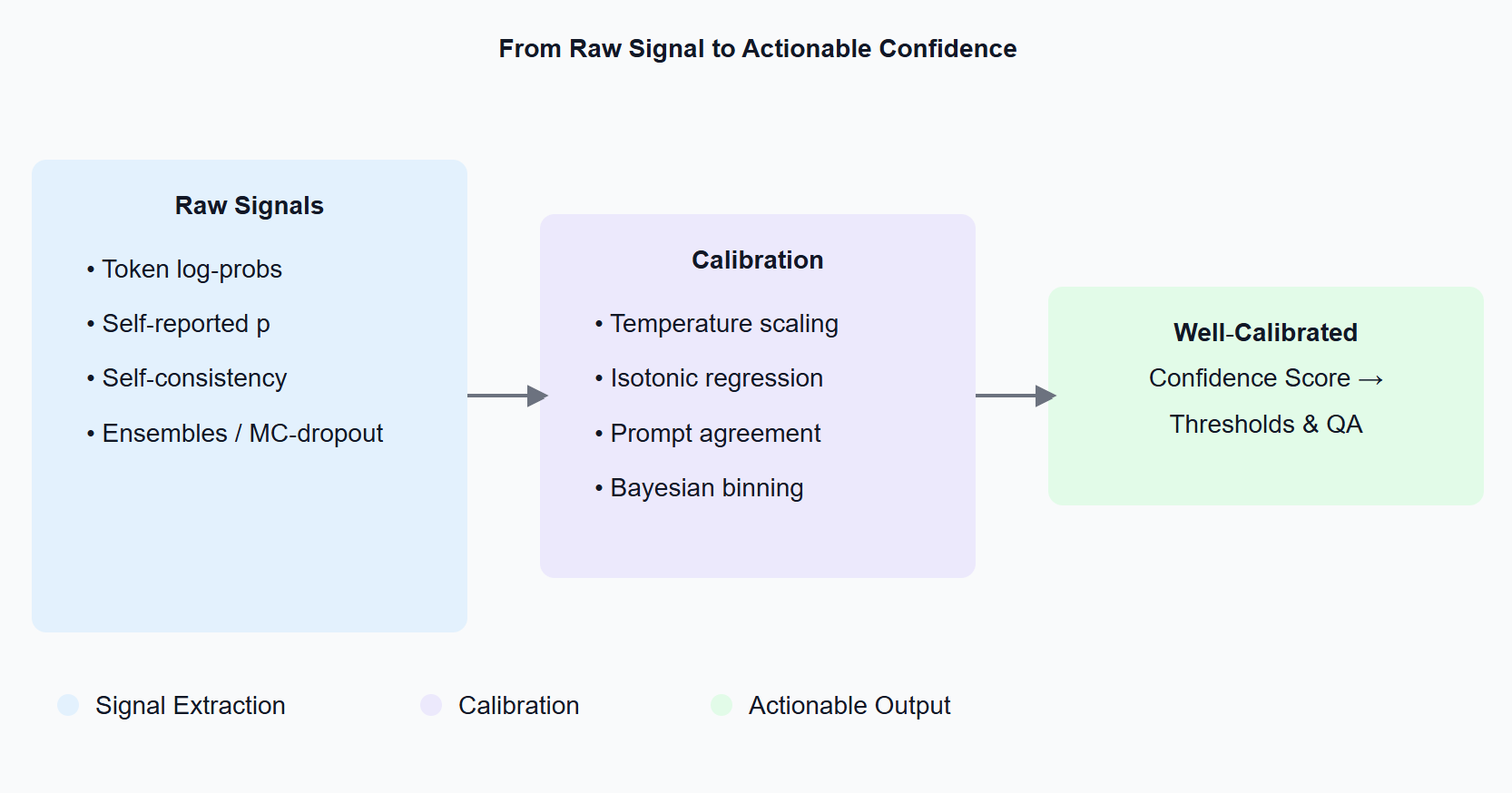
Confidence Measures Diagram
1 De inzet: waarom vertrouwen belangrijk is
Stel u voor: een douane‑afhandeling‑workflow die goederenbeschrijvingen automatisch classificeert. Een 90%‑zekere misclassificatie triggert een handmatige review; een 99%‑zekere gaat er soepel doorheen. Zonder gekalibreerde waarschijnlijkheden overspoelt u mensen met valse alarmen of, erger nog, laat u kostbare fouten door. Vertrouwensscores veranderen 'black‑box magie' in een controleerbaar onderdeel van uw beslissingspijplijn.
2 Waar komen vertrouwenssignalen vandaan?
Token log‑waarschijnlijkheden. De meeste model‑API's (OpenAI, Anthropic, Mistral, llama‑cpp, …) retourneren logprobs als u de vlag zet. Aggregeer de waarschijnlijkheidsmassa toegewezen aan elke klasse‑token-dat is uw ruwe score.
Zelf‑gerapporteerde waarschijnlijkheden. U kunt simpelweg vragen: "Geef het label en een waarschijnlijkheid tussen 0 en 1." Het model zal gehoorzamen-verrassend goed, maar meestal overmoedig.
Self‑consistency sampling. Prompt het model opnieuw of sample het meerdere keren. Als de antwoorden verschillen, behandel het als onzekerheid (zie SelfCheckGPT).
Ensembles & MC‑dropout. Klassieke model‑onzekerheid‑trucs werken nog steeds: run meerdere checkpoints of schakel dropout in bij inferentie om een verdeling van logits te krijgen.
3 Van ruwe scores naar betrouwbare cijfers: kalibratie 101
LLMs zijn meestal verkeerd gekalibreerd uit de doos (de 80%‑vertrouwen‑bucket kan maar 60% van de tijd gelijk hebben). Post‑hoc kalibratie lost dit op:
- Temperatuur/Platt schaling – leer één scalaire T op een validatieset; deel logits door T.
- Isotonische regressie – een niet‑parametrische monotone mapping voor multi‑klasse taken.
- Prompt‑agreement kalibratie – gemiddelde log‑probs over diverse templates.
- Bayesiaanse binning of ensemble temperatuur schaling – best voor veiligheidskritieke domeinen.
Evalueer met Expected Calibration Error (ECE) of Brier score; streef naar ECE < 2% op uitgehouden data.
4 Hands‑on: Een zero‑shot spam classificeerder kalibreren
Het onderstaande fragment toont de essentie:
import openai, numpy as np, json, math
LABELS = { "A": "spam", "B": "not spam" }
def classify(text, T=1.0):
prompt = f"Classificeer de volgende tekst als A) spam of B) geen spam.\nTEKST: {text}\nAntwoord met één letter."
resp = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=[{ "role": "user", "content": prompt }],
logprobs=True,
top_logprobs=5,
temperature=0
)
# pak de logprob voor het eerste token (A of B)
first_tok = resp.choices[0].logprobs.content[0]
logps = resp.choices[0].logprobs.token_logprobs[0]
# converteer naar dict {token: p}
probs = {tok: math.exp(lp / T) for tok, lp in zip(first_tok, logps) if tok in LABELS}
Z = sum(probs.values())
probs = {LABELS[tok]: p/Z for tok, p in probs.items()}
return max(probs, key=probs.get), probs
Wat er gebeurt:
- We vragen logprobs aan van de API.
- Converteer ze naar lineaire ruimte en temperatuur‑schaal.
- Normaliseer en retourneer een nette {label: waarschijnlijkheid} woordenboek.
Verzamel ~200 gelabelde voorbeelden, fit T op een uitgehouden split (minimaliseer negatieve log‑likelihood), en u heeft gekalibreerde spam‑waarschijnlijkheden die u kunt drempelen in productie.
5 Veelvoorkomende valkuilen
Kleine kalibratie‑sets. Onder ~100 voorbeelden domineert de variantie; bootstrap‑gemiddelde ECE om het bij te houden.
Distributieverschuiving. Hercontroleer kalibratie wanneer databronnen of prompt‑templates veranderen.
Overmoedigheid van few‑shot priming. Extra voorbeelden verbeteren nauwkeurigheid maar maken kalibratie vaak slechter-fit T opnieuw wanneer u de prompt aanpast.
6 Wanneer log‑probs niet beschikbaar zijn
Als uw provider token‑waarschijnlijkheden verbergt, val terug op zelf‑gerapporteerd vertrouwen of self‑consistency sampling. Beide correleren met nauwkeurigheid; beide profiteren van dezelfde kalibratie‑trucs.
7 Belangrijkste punten
- Vertrouwensscores verbergen zich al in uw LLM-extraheer en kalibreer ze.
- Temperatuur‑schaling is een 10‑regel, hoge‑ROI oplossing.
- Houd altijd ECE/Brier bij op verse data.
- Texterous kan gekalibreerd LLM‑vertrouwen integreren in uw bestaande pijplijnen-neem contact met ons op om uw use case te bespreken.
Verder lezen
- Desai & Durrett (2020) Calibration of Pre‑trained Transformers
- Jiang et al. (2023) Self‑Check: Detecting LLM Hallucination via Argument Consistency
- Minderer et al. (2023) Improved Techniques for Training Calibrated Language Models